-
- Cisco
- 724
- 2024-01-17
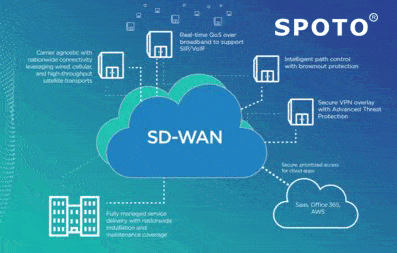
SD-WANs are considered to be a new form of corporate connectivity, which would be designed for adapting to modern IT practices as well as the connections to the cloud. In the past, corporations that would be building their own WANs utilizing proprietary hardware as well as service-provider network connections amongst the data centers, but that would be all changing. Applications are considered to be moving to the cloud and Internet broadband costs would be declining, paving the way to creating virtual WANs that would be tied together for leveraging Internet broadband utilizing software and COTS hardware (commodity off-the-shelf).
Before we check out some of the components of Cisco SD-WAN, if you would be looking for more knowledge, you could check out the training courses which would be offered by the SPOTO Club.
SD-WAN for Router Replacement
Technology professionals would like to talk about “use cases” for emerging technology. These would be useful reference points for why the technology would be purchased or implemented, though they aren’t the be-all or end-all. The SD-WAN market would be containing many use cases as well as features that would be appealing to the different enterprises as well as service providers. Many of the SD-WAN vendors and managed service providers would be focusing on specific niches. For that reason, we would have to try to highlight some of the specific requirements as well as features being sought by specific customers.
One of the more popular functions of SD-WAN is considered to be the router replacement or router consolidation. One of the higher costs of WAN frequently cited by enterprise customers is considered to be the operating expense (OPEX) of managing proprietary hardware as well as CPE (customer premises equipment), which would be including branch-office routers. Additionally, hiring certified specialists for managing these branch-office routers is quite expensive.
SD-WAN Security Functions
Another allure of SD-WAN technology is that it could be utilized for deploying security functions like the VPN (virtual private network) as a software overlay utilizing end-to-end encryption. This would be able to help you to meet security requirements for businesses that might wish to connect branch offices or retail outlets but would be also having high-security requirements.
SD-WANs, because they would be virtual networks controlled from the cloud, also have the suppleness to plug in additional security functions without specialized hardware. Value-added security services like the stronger encryption as well as IDS (intrusion detection services) could be offered by the SD-WAN providers. This could be a matter for debating, as some SD-WAN providers would believe some security services, like the UTM (unified threat management), would be required to be distributed to the cloud, due to the necessary compute power. There would be a wide variety of approaches in how security functions would be running in SD-WAN, whether they would be hosting on an appliance or in the cloud.
Why does SD-WAN Will continue to Grow?
You might now gain the picture; there would be many functions as well as utilizes cases for SD-WAN technology that could be delivering a direct ROI (return on investment). Whether an enterprise would be looking for reducing the cost of opex by replacing proprietary routers, saving network costs by replacing or augmenting MPLS, and just move to a more modern platform that would be yielding more flexibility, it is clear that SD-WAN is considered to be one of the hottest markets in technology. It would be also driven by incumbent network players like the Cisco as well as VMware to make big-ticket acquisitions for getting ahead of the curve.
For having more details about the Cisco SD-WAN Components, you should check out the training courses which are being offered at the SPOTO Club, if you wish to achieve success in a single attempt.
-
- Cisco
- 436
- 2024-01-17
Introduction
VTP (VLAN Trunking Protocol), which is a Cisco proprietary protocol. In a slightly larger network, there will be multiple switches, as well as multiple VLANs. If you create VLANs on each switch separately, this will be a heavy workload. Assuming that there are M switches in the network and a total of N VLANs are divided, in order to ensure the normal operation of the network, it is necessary to create N VLANs on each switch, a total of M × N VLANs, as M and N increase, This task will be boring and heavy.
The VTP protocol can help us reduce these boring and heavy tasks. The administrator sets up one or more VTP servers in the network, and then creates and modifies VLANs on the server. The VTP protocol will notify these changes to other switches, and these switches update the VLAN information (VLANID and VLAN Name). VTP makes the management of VLANs much more automated.
II. Principle
VTP Domain : It is composed of switches that need to share the same VLAN information. Only switches in the same VTP domain (that is, VTP domains with the same name) can synchronize VLAN information.
I. Server (server mode):
VLANs can be created, modified, and deleted on the VTP server. At the same time, this information will be advertised to other switches in the domain on the trunk link; after receiving the VTP notifications from other switches, the VTP server will change its own VLAN information and forward it. The VTP server will save the VLAN information in NVRAM (that is, the flash: vlan.dat file), that is, these VLANs will still exist after restarting the switch. By default, the switch is in server mode. Each VTP domain must have at least one server, of course, there can be multiple.
II.Client (client mode):
It is not allowed to create, modify and delete VLANs on the VTP client, but it will listen to VTP announcements from other switches and change its own VLAN information. The received VTP information will also be forwarded to other switches on the trunk link, so this The switch can also act as a VTP trunk; the VTP Client saves the VLAN information in RAM, which will be lost after the switch restarts. 3) Transparent (transparent mode): The switch is not fully involved in VTP. You can create, modify, and delete VLANs on switches in this mode, but these VLAN information will not be advertised to other switches, and it will not accept VTP notifications from other switches and update its own VLAN information. However, it will forward the received VTP announcement through the Trunk link to act as the outstanding color of the VTP trunk, so the switch can be regarded as transparent. VTP Transparent only saves the VLAN information on this switch in NVRAM. 4) VTP pruning The VTP pruning function automatically calculates which links should prun which VLAN packets, and the administrator only needs to enable this function.
III.Purpose
Master Trunk configuration
Master VTP basic operations
Understand the difference between VTP roles
Topology and requirements Topology:
Demand:
The line between SW1, SW2 and SW3 needs to be configured as Trunk, using Dot1q encapsulation protocol
SW1 is VTP Server mode, SW2 is VTP Transparent mode, SW3 is VTP Client mode, Domain name is SPOTO, and VTP password is P @ s5w0rd
Create VLAN 10 named VTP-Server on SW1 and VLAN 20 named VTP-Transparent on SW2, and observe the VLAN database and VTP status of SW1 ~ 3
Configuration and implementation
The line between SW1, SW2 and SW3 needs to be configured as Trunk, using Dot1q encapsulation protocol
SW2
SWX(config)#interface ethernet 0/0
SWX(config-if)#switchport trunk encapsulation dot1q
SWX(config-if)#switchport mode trunk
SWX(config)#interface ethernet 0/1
SWX(config-if)#switchport trunk encapsulation dot1q
SWX(config-if)#switchport mode trunk
SW1 is VTP Server mode, SW2 is VTP Transparent mode, SW3 is VTP Client mode, Domain name is SPOTO, VTP password is P @ s5w0rd, VTP version 2
SW1 SW1(config)#vtp version 2
SW1(config)#vtp mode server
//Device mode already VTP Server for VLANS.
SW1(config)#vtp domain SPOTO
//Changing VTP domain name from NULL to SPOTO
SW1(config)#vtp password P@s5w0rd
//Setting device VTP password to P@s5w0rd
IOS default VTP mode is Server, domain name and password are empty
SW2 SW2(config)#vtp version 2
SW2(config)#vtp mode transparent
//Setting device to VTP Transparent mode for VLANS.
SW2(config)#vtp domain SPOTO
//Domain name already set to SPOTO.
SW2(config)#vtp password P@s5w0rd
//Setting device VTP password to P@s5w0rd SW3 SW3(config)#vtp version 2
SW3(config)#vtp mode client
//Setting device to VTP Client mode for VLANS.
SW3(config)#vtp domain SPOTO
//Changing VTP domain name from NULL to SPOTO
SW3(config)#vtp password P@s5w0rd
//Setting device VTP password to P@s5w0rd
Create VLAN 10 named VTP-Server on SW1 and VLAN 20 named VTP-Transparent on SW2. Observe the VLAN database and VTP status of SW1 ~ 3 SW1 SW1(config)#vlan 10
SW1(config-vlan)#name VTP-Server SW2 SW2(config)#vlan 20
SW2(config-vlan)#name VTP-Transparent
The *** MD5 digest checksum mismatch on trunk: Et0 / 0 *** message appears here, do n’t care, SW2 is in transparent mode, and the VLAN database of SW1 will not be synchronized and synchronized, so it is normal for MD5 check to be inconsistent
Check the MD5 digest part of SW1 and SW3, if this part is completely consistent, it means that VTP has been synchronized
IV. VTP troubleshooting
In many cases, after completing the conventional configuration, you cannot learn VLAN information. You can use the show vtp status command to view the comparison between the previous device and the VTP Server role switch. Please focus on the following points:
SW # show vtp status
VTP Version:
2 // VTP version is consistent, if not consistent, you need to configure Configuration Revision: 0
Maximum VLANs supported locally: 255
Number of existing VLANs: 5
VTP Operating Mode: Client
// Confirm the working role of the current switch VTP Domain Name: Whether the domain of cisco
// switch is the same as the switch in server mode VTP Pruning Mode: Disabled
VTP V2 Mode: Disabled
VTP Traps Generation: Disabled
MD5 digest: 0xAA 0xB9 0x0C 0xCD 0xD7 0xE8 0xA6 0xE0
// Whether the switch password is consistent with the server mode switch, if not consistent, please confirm and reconfigure
V. Explanation of VTP configuration commands:
Vtp domain domain name Create a VTP domain under "Global" or "VLAN database"
Vtp mode server | client | transparent
//Configure the switch's VTP mode under "Global"
Vtp server | client | transparent
// Configure the VTP mode of the switch in the "VLAN database"
Vtp password Password
//Configure the VTP password in "Global" or "VLAN Database"
Vtp pruning
//Configure VTP pruning in "Global" or "VLAN Database"
Vtpversion2
//Configure the version of VTP under "Global"
Vtp v2-mode
//Configure VTP pruning in the "VLAN database"
Show vtp status
//View the configuration information of VTP under "Privilege"
Swichport trunk encapsulation protocol (dot1q or ISL) under "interface", encapsulate the trunk protocol
Note: if you are interested in this blog, and you can follow SPOTO where we have updated related technologies. besides, SPOTO provides various certified exams dumps that cover all real exam answers and questions. you can contact us.
-
- Cisco
- 860
- 2024-01-15
To fully understand BGP, we must first answer the following seemingly simple questions: why BGP is needed, that is, how BGP is generated, and what problems does it solve. With the above questions, let us briefly review the development trajectory of a routing protocol.
First of all, the essence of routing is to describe the expression of a network structure. The routing table is actually a collection of results. In the early ARPANet network era, the network scale was limited and the number of routes was not large. Therefore, all routers can maintain the entire network topology. The routing protocol used at that time was called GGP (Gateway-to-Gateway Protocol). GGP naturally became the first internal gateway protocol (IGP).
At that time, network managers encountered a similar problem to today: the number of routes caused by the expansion of the network scale continues to increase. In order to solve this problem of network size growth, an autonomous system concept (AS) is proposed, which can also be called a routing management domain. Use one routing protocol inside the AS, and then use another routing protocol between the AS. The benefits of this are obvious. Different networks can choose the IGP protocol and then interconnect through a unified inter-AS protocol.
In the development field of IGP, first RIP became the mainstream of IP routing, and then more advanced IGP protocols including OSP and ISIS appeared. These protocols are more automated, smarter and more reliable. There is a mutual trust relationship between routers in the same AS, and these routers are often maintained by the same management personnel. Therefore, IGP's automatic discovery and routing calculation information flooding are completely open, and there is relatively little manual intervention.
The need for interconnection of different ASs has promoted the generation of external gateway protocol (EGP). The main purpose of EGP is to transfer routing protocols between different ASs. And different ASs are often directly connected, most AS interconnection behavior only involves a small number of border routers (ASBR), so the design of EGP is also very simple. EGP's RFC827 was released in 1982, and it seems to be earlier than RIP's first standard FRC1058, but in fact RIP has been widely used before RFC1058. At the time, RIP + EGP became a standard routing combination.
EGP was designed so simple that it quickly failed to meet the requirements of network management. EGP simply publishes network reachability information without making any optimization or considering loop avoidance. Some people even think that EGP is not a routing protocol. Many of EGP's shortcomings are eventually replaced by BGP. BGP's first FRC1105 was released in 1989. Compared with EGP, BGP is more like a routing protocol, with many routing protocol features, such as solving loop problems, convergence problems, triggering updates, and so on.
It's like different companies have their own corporate culture and standards, but the interaction between companies must follow a unified code of conduct and standards. There must also be a unified standard for routing interaction between ASs. The many advantages of BGP over EGP make BGP the only external gateway protocol and widely used on the Internet.
In summary, BGP is an external gateway protocol that appears to replace EGP. It must be able to perform route selection, avoid routing loops, be able to deliver routes more efficiently, and maintain a large number of routes. Because BGP is deployed between ASs that do not have a complete trust relationship, BGP needs to have rich routing control capabilities, and BGP can be extended through some simple and uniform methods.
BGP development
BGPv1 (RFC1105) defines some of the most basic protocol features of BGP. BGP passes routes between ASs, so it is very important. In order to ensure the reliable transmission of BGP, TCP is used as the transport layer protocol. The advantages of using TCP are obvious. BGP can use TCP's existing reliable transmission mechanism, retransmission, sequencing and other mechanisms to ensure the reliability of protocol message interaction. The benefits of TCP extension can also be inherited, for example, MD5 authentication of TCP can be used by BGP.
BGP is established between two different AS and there is a trust problem. Therefore, BGP cannot be discovered automatically. Instead, it needs to manually configure neighbors and establish TCP relationships using specified addresses. The BGP relationship established with AS external nodes is called EBGP relationship, and the BGP relationship established with AS internal nodes is IBGP relationship.
One of the most important concepts of BGP is to use the AS number to solve the loop problem between AS. If a certain routing information is received with its own AS number, it means that this route is a known route and it will not be processed anymore. If the AS number is duplicated, it means that there is a routing loop. There is no concept of AS-path in BGPv1, and this concept is made clear in BGPv2. BGP is constantly improving from v1, v2, v3, and now v4. BGP4 + is mainly an extension of multi-protocol BGP, also known as MP-BGP. The concept of MP-BGP will not be discussed in this article.
Within the AS, because there is no change in the AS number, other methods are needed to prevent loops. BGP stipulates that the routes learned from IBGP neighbors will not be passed to another IBGP neighbor. Simply put, the route between IBGPs will only be transmitted by one hop, and the route will only be transmitted once. Of course, there is no problem of looping. At the same time, all routers within the AS are required to establish IBGP relationships in pairs. This is the BGP full connection in BGP technology. Full connectivity is unthinkable in a large network, so two technologies (RFC1966 and RFC1965) were later derived from route reflector and BGP alliance.
The route reflector designates a node as a reflector in the AS, all other nodes establish an IBGP relationship with the reflector, and the reflector acts as an intermediate node to pass routes between any other two IBGPs. Therefore, in theory, the reflector should not change the path attribute information when routing, otherwise it will destroy the principle of BGP avoiding loops inside the AS. However, from the perspective of practical application, different vendors have made many features on the function of the reflector, which requires careful use by BGP deployers. The BGP alliance is re-planned within the AS, and a flat AS is divided into multiple private ASs. The benefits of doing this can be a layered management of a large AS on the one hand, and on the other hand through the layer , Naturally reducing the need for full connectivity.
BGP messages use the TLV structure, which is very conducive to expansion and backward compatibility. Therefore, with the development of the network, a large number of RFCs on BGP extensions have been generated, which makes BGP an external gateway protocol that keeps youth forever.
-
- Cisco
- 1959
- 2024-01-18
I. EIGRP Concept
EIGRP uses the Diffused Update Algorithm (DUAL) algorithm to calculate the shortest path to the target network. EIGRP is a private routing protocol invented by Cisco, developed from IGRP, but the algorithm has been greatly changed. EIGRP is the same as IGRP and RIP. A dynamic routing protocol using DV algorithm.
The algorithm of EIGRP has been greatly changed.Although it is a dynamic routing protocol that uses DV algorithm like IGRP and RIP, it has greatly improved the convergence speed, occupied network bandwidth and system resources, and has fast convergence For loopless route calculation, the DUAL update algorithm EIGRP can ensure that 100% does not form a loop.
The convergence speed makes it impossible for the EIGRP protocol to generate loop routes in route calculation, and the convergence time of route calculation is also well guaranteed.
Because the DUAL algorithm allows EIGRP to calculate the route, it will only recalculate the changed route; for a route, only the router affected by this route will be involved in the route recalculation. During normal operation, the network resource utilization rate is very low; only Hello packets are transmitted on a stable network. EIGRP can also control the EIGRP packets sent, reducing the occupation rate of EIGRP packets on the interface bandwidth, thereby avoiding the continuous sending of a large number of routing packets Things that affect the normal data business occur.
EIGRP (Enhanced Interior Gateway Routing Protocol) employs critical metrics such as AD (Administrative Distance), FD (Feasible Distance), FC (Feasibility Condition), and FS (Feasible Successor) to optimize routing decisions.
In EIGRP, AD represents the trustworthiness of a route, and lower values indicate higher reliability. The routing table lists routes learned from multiple routing protocols, each with its AD. To modify the administrative distance for a specific protocol, like EIGRP, use commands such as "r1 config router distance."
FD, on the other hand, measures the total cost of reaching a destination, computed by routers. EIGRP uses this metric to select the best path to a destination network.
FC is crucial in EIGRP's topology database, where it ensures that only routes satisfying the condition (AD < FDmin) are stored as feasible successors.
To view EIGRP routes and their metrics, employ the "show ip route command." In situations where redundancy is essential, a floating static route can provide backup options. Routers like R1 can thus make efficient routing decisions based on these metrics for a resilient network infrastructure.
II. What is eigrp dual algorithm
Although EIGRP is a distance vector routing protocol, after receiving a route from a neighbor, it is not directly used in the routing table without any calculation. EIGRP will put all the routes received from the neighbor into the topology database (Topology Database ), The optimal route is put into the routing table after calculation by DUAL's acyclic algorithm; because EIGRP may have multiple neighbors or may receive the same route from multiple neighbors, it is necessary to select the optimal route from Routes are put into the routing table for use instead of the optimal route. The route is backed up in the topology database. After the route in the routing table fails, the alternate route is searched from the topology database and placed in the routing table.
After EIGRP puts the routing information received from neighbors into the topology database, it needs to select the optimal route through the DUAL algorithm. DUAL is a convergence algorithm, which replaces the Belloman-ford algorithm used for other distance vector protocols. The design idea of the DUAL algorithm is that even a temporary routing loop will damage the performance of a network, so in order to break the routing loop at any time, a distributed shortest path routing is performed using diffusion calculation.
The DUAL algorithm has several important terms--AD / FD / FC / FS
III. AD value
For the router E, the metric value of the B\C \ D routers reaching the Z network respectively is called the AD value of E. That is, the distance from the neighbor to the destination network segment (advertised distance), such as the E-B-Z path, for the E router, its AD value is 10.
IV. FD value
For router E, the total metric of the path reached by E-B-Z, called the FD value of E, is calculated from the local router to the sum of the metrics between the target networks. For example, the path of E-B-Z, for the E router, its FD value is : 20 (E-B) + 10 (B-Z) = 30; there may be multiple paths to the destination in the EIGRP topology database, and the optimal one put in the routing table is called the easy distance (FD)
V. Successor router:
The successor is a directly connected neighbor router, through which it has the shortest route to the destination. That is, the next-hop router with FD min In the three paths of E-B-Z, E-C-Z, and E-D-Z, C is the successor router for E, because the FD of E-C-Z is 20
Feasible successor router (FS) value:
Because there may be multiple paths in the topology database to reach the destination, but the one selected as the optimal FD is put into the routing table, and the alternate route left in the topology database is called Easy Successor (FS ), Choose FS must meet FC conditions.
VI. FC value:
There can be up to 6 FSs in the topology database. If an EIGRP has 8 neighbors that can go to the destination, after selecting an FD and putting it into the routing table, not all the other 7 can be stored in the topology database. The topological database can only have a maximum of 6 (including FD), and it is not necessarily that 6 will be put into the topological database, because to be stored in the topological database, it must meet certain conditions, called Feasibility Condition ( FC), if AD <FDmin is satisfied, it is considered feasible, and the path of this neighbor can exist in the topology database.
Take the above diagram as an example, FDmin = 20, and the FC condition must be satisfied, that is, AD <20.
For the three paths of E-B-Z, E-C-Z, and E-D-Z, the AD of E-B-Z is 10, the AD of E-C-Z is 10, and the AD of ED-Z is 25, so only the two paths of E-B-Z and E-C-Z satisfy the FC condition, that is, only the two of E-B-Z and E-C-Z The path will be selected into the topology database.
VII. View the routing table:
R11#sh ip route eigrp Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
a - application route
+ - replicated route, % - next hop override
Gateway of last resort is not set
145.12.0.0/32 is subnetted, 1 subnets
D 145.12.12.12 [90/1603] via 145.67.89.2, 00:04:42, Ethernet0/0
145.67.0.0/16 is variably subnetted, 5 subnets, 2 masks
D 145.67.89.16/30 [90/1203] via 145.67.89.2, 00:04:42, Ethernet0/0
For the route 145.12.12.12, its default AD value is 90 and FD value is 1603.
VIII. R11#sh ip eigrp topology
EIGRP-IPv4 Topology Table for AS(145)/ID(145.11.11.11)
Codes: P - Passive, A - Active, U - Update, Q - Query, R - Reply,
r - reply Status, s - sia Status
P 145.67.89.16/30, 1 successors, FD is 1203
via 145.67.89.2 (1203/1103), Ethernet0/0
P 145.12.12.12/32, 1 successors, FD is 1603
via 145.67.89.2 (1603/501), Ethernet0/0
View routes that meet FC conditions in the topology database
-
- Cisco
- 774
- 2024-01-17
Foreword:
The Domain Name System (DNS) is the Internet's phone book. Map IP addresses that are difficult for humans to remember to be relatively easy to remember in English, provide network services, and access information online through domain names such as nytimes.com or espn.com Web browsers interact through Internet Protocol (IP) addresses. DNS converts domain names to IP addresses so that browsers can load Internet resources.
Each device connected to the Internet has a unique IP address that other computers can use to find the device. The DNS server does not require human memory IP addresses, such as 192.168.1.1 (in IPv4), or more complex new alphanumeric IP addresses, such as 2400: cb00: 2048: 1 :: c629: d7a2 (in IPv6).
DNS domain name structure
Each IP address can have a host name. The host name is composed of one or more character strings, and the strings are separated by a decimal point through the host name. The process of finally obtaining the IP address corresponding to the host name is called domain name resolution.
Generally, the domain name structure of an Internet host is: host name. Third-level domain name. Second-level domain name. Top-level domain name. The Internet's top-level domain name is registered and managed by the Internet Network Association's domain name registration query committee responsible for network address allocation. It also assigns a unique IP address to each host on the Internet.
Top-level domain:
Cn --- is China
Us ---is the United States
Jp ---is Japan
secondary domain:
.com---Generally used for commercial institutions or companies
.net---Generally used for organizations or companies engaged in Internet-related network services
.top---generally used for enterprises and personal organizations
.org---generally used for non-profit organizations and groups
.gov---for government departments
How does DNS work?
Enter the www.baidu.com domain name in the browser. The operating system will first check whether its local hosts file has this URL mapping relationship. If so, it will first call this IP address mapping to complete the domain name resolution.
If there is no mapping of this domain name in the hosts, then look up the local DNS resolver cache, if there is this URL mapping relationship, if there is, return directly to complete the domain name resolution.
If there is no corresponding URL mapping relationship between the hosts and the local DNS resolver cache, we will first find the preferred DNS server set in the TCP / IP parameters, here we call it the local DNS server,
When this server receives the query, if the domain name to be queried is included in the local configuration area resource, it will return the resolution result to the client to complete the domain name resolution. This resolution is authoritative.
If the domain name to be queried is not resolved by the local DNS server area, but the server has cached this URL mapping relationship, then this IP address mapping is called to complete the domain name resolution, which is not authoritative.
If both the local zone file and the cache resolution of the local DNS server are invalid, query according to the settings of the local DNS server (whether or not to set a forwarder),
If the forwarding mode is not used, the local DNS will send the request to the "root DNS server". After receiving the request, the "root DNS server" will determine who the domain name (.com) is to authorize management and return a responsible domain name. An IP of the server.
After the local DNS server receives the IP information, it will contact the server responsible for the .com domain. After the server responsible for the .com domain receives the request, if it cannot resolve it,
It will find a lower DNS server address (baidu.com) that manages the .com domain to the local DNS server. When the local DNS server receives this address, it will find the baidu.com domain server, repeat the above actions, and query until it finds the www.baidu.com host.
If the forwarding mode is used, the DNS server will forward the request to the upper-level DNS server for resolution by the upper-level server. , Cycle through this.
Regardless of whether the local DNS server is used for forwarding or root hints, the result is finally returned to the local DNS server, and then the DNS server is returned to the client.
Inquiry mode
The query from the host to the local domain name server is generally recursive.
The so-called recursive query is: if the local domain name server inquired by the host does not know the IP address of the domain name being queried, the local domain name server acts as a DNS client,
Instead of sending the host to perform the next query, it will continue to send query request messages to other root domain name servers (that is, continue to query for the host).
Therefore, the query result returned by the recursive query is either the IP address to be queried, or an error is reported, indicating that the required IP address cannot be queried.
A
Iterative query of the local domain name server to the root domain name server.
Features of iterative query: When the root domain name server receives the iterative query request message from the local domain name server, it either gives the IP address to be queried or tells the local server: "Which domain name server should you query next" .
Then let the local server perform subsequent queries. The root domain name server usually tells the local domain name server the IP address of the top-level domain name server that it knows, and then the local domain name server queries the top-level domain name server.
After receiving the query request from the local domain name server, the top-level domain name server either gives the IP address to be queried, or tells the local server which authority domain name server to query next.
Finally, know the IP address to be resolved or report an error, and then return this result to the host that initiated the query
Basic configuration example
SERVER (config) #ip dns server //Enable its own ability to resolve domain names
SERVER (config) #ip host r1 192.168.1.1 //On the DNS server, create a 'parse entry'
SERVER (config) #ip host r2 192.168.1.2 //On the DNS server, create a 'parse entry'
CLIENT (config) #ip name-server 192.168.1.1 //Set the DNS server, that is, point to the DNS server IP, when there is no resolution entry locally, iteratively query the next server
CLIENT # telnet r1
(Execute the telnet command to check)
Translating "r1"… domain server (192.168.1.1) [OK]
-
- Cisco
- 474
- 2024-01-16
I. Foreword
Although 5G is currently the hottest communication technology, from the national level to major commercial companies to every ordinary consumer, almost everyone is concerned about how the new generation of communication technology can improve the performance of mobile phones, and how can help people make Life is better.
However, the innovation of network technology is not limited to 5G, there are more technologies to improve the experience together, such as Wi-Fi 6, which has recently been attracting more attention. This latest wireless local area network standard is about to play a role in the future of the further explosion of equipment scale, and has become the preferred technology for building wireless networks in homes, offices, and public places.
II. What is Wi-Fi 6
The Wi-Fi 6 standard was officially released in mid-2019. It is the latest version of the IEEE 802.11 wireless LAN standard and provides compatibility with previous network standards. It also includes 802.11n / ac, which is now mainstream. The name defined by the Institute of Electrical and Electronics Engineers is IEEE 802.11ax, and the Wi-Fi Alliance, which is responsible for commercial certification, is called Wi-Fi 6 for publicity.
The previous 802.11n / ac was also renamed Wi-Fi 4 and Wi-Fi 5 in this rebranding movement. This is of great benefit to equipment manufacturers, no longer need to spend effort to educate users, or come up with fancy marketing vocabulary, simple numbers can explain the pros and cons of the product.
The birth of the Wi-Fi 6 name has brought this technology closer to consumers. It has become an easy-to-understand technical term like 5G. Wi-Fi has also begun to transform into a consumer-oriented commercial brand, which is no longer a pure technical standard, and has a broader prospect on the road of network technology evolution.
Wi-Fi 6 introduces a number of new technologies, which have greatly improved the communication quality, transmission efficiency, energy consumption performance, and multi-device accommodation of wireless networks. The theoretical maximum rate through 160MHz channels can reach 9.6Gbps.
The introduction of OFDMA (Orthogonal Frequency Division Multiple Access) makes the data content in transmission no longer rigidly occupy the entire channel, divides the data into more detailed resource blocks for management and transmission, and realizes more efficient use of the network. It is like a large truck, from one car to one car regardless of size to a reasonable distribution. Each truck is filled to maximize the single transportation.
TWT (Timed Wakeup) makes Wi-Fi 6 more power-saving, which is helpful for mobile devices such as mobile phones and Internet of Things devices. The connection between the device and the wireless router will sleep and wake up regularly, which is equivalent to the combination of work and rest instead of working all day, which improves the power consumption performance and transmission efficiency on both sides.
The modulation method enhanced to 1024-QAM makes the data transmission and reception process more compact, and more information can be transmitted under the same signal.
Compared with Wi-Fi 5's 256-QAM, the speed can be increased by 25%. Wi-Fi 6 also uses two frequency bands, 2.4 GHz and 5 GHz, and multi-band transmission and reception reduces the embarrassment of being idle while the network is congested.
BSS Coloring allows the signal source to have its own "color". Up to 63 "colors" give mobile phones and other terminals an efficient way to find routers. Similar to the different theme colors of different take-out services, after dyeing, the router and terminal equipment can find each other more accurately and efficiently, and the communication power and time are reduced.
Wi-Fi 6 uses MU-MIMO technology in both uplink and downlink, allowing routers to use multiple antennas to communicate with multiple terminal devices at the same time, so as to achieve "multi-purpose". Compared with the design that only single antenna and single device can communicate at the same time in the past, MU-MIMO is more capable of increasing network speed and connecting more devices.
III. Why is the era of Wi-Fi 6 coming
A new standard becomes the product standard and is popularized in the market. It often needs to go through the process of the standard release, related component follow-up, product listing, and finally cost reduction and price acceptance by consumers. It is less than half a year before the official release, and the Wi-Fi 6 has been released in the early version for almost two years. How can it usher in its own time so quickly?
Although the router is a product that has not changed its power for a long period of time, most consumers have not realized the value of high-priced products, and the routers as the first Wi-Fi 6 products are high-end products at a price of 3,000 yuan. , And did not launch low-end and mid-range products anytime soon, and the popularity seems far away.
The important reason for the acceleration of Wi-Fi 6 is actually the enthusiasm of mobile phone manufacturers in introducing new standards, and high-end products have played a pioneering role in the entire market. The two flagship mobile phone products in 2019, the Galaxy S10 series and the iPhone 11 series, took the lead in applying this technology so that a larger consumer base itself has noticed Wi-Fi 6.
At the same time that market attention has been achieved, the Wi-Fi 6 standard has also been officially released, allowing related products of upstream manufacturers to enter the market one after another. The introduction of router chips, PC network cards, mobile phone chips, and other products has enabled the Wi-Fi 6-based ecosystem to be built, covering high-end, low-end positioning, and promoting the explosion of terminal products.
Personal terminal products mainly based on mobile phones and notebooks have shown consumers' demand for network improvement, forcing router manufacturers to follow up related products.
Consumers are waiting for wireless network upgrade The changes in the network environment are also the factors driving Wi-Fi 6's attention.
The speed and quality of the network brought by the 5G network are unforgettable for those who have experienced it. However, the monthly traffic limit and 5G coverage prevent people from getting the same network performance at home or other indoor environments.
At the same time, Gigabit networks have begun to spread throughout the country, and they have entered more homes in the context of growth and fee reductions. In Shanghai, they only need a 199-month fee to use Gigabit networks. There are not many routers that can release Gigabit network capabilities, and this is precisely the scenario where Wi-Fi 6 matches the theoretical performance.
IV. Wi-Fi 6 coming in the first year
It can be said that 2020 will be the 6th year of Wi-Fi.
Although the first batch of products did not enter the market this year, it has really spread to the masses of consumers and related products of different consumption levels are expected to become the mainstream of sales in the market this year. We will continue to pay attention to what kind of performance Wi-Fi 6 will bring and what new direction it can lead.
-
- CISSP
- 785
- 2024-01-18
Before we discuss the Best Video Tutorial, you could gain for the CISSP Training, it is necessary that we first obtain the knowledge regarding the same.
What is CISSP?
CISSP is believed to be an autonomous information security certification that would be governed by International Information Systems Security Certification Consortium or (ISC)².
A Certified Information Systems Security Professional (CISSP) is an information assurance professional who defines the devise management, architecture, and/or controls that would be guarantying the security of business atmospheres. CISSP was believed to be the initial credential in the field of information for meeting the severe requirements of ISO/IEC Standard 17024. CISSP is considered to be an intention measure of excellence and an internationally recognized standard of attainment.
In June 2004, the CISSP became the first information security credential accredited by ANSI ISO/IEC Standard 17024:2003 accreditation. In the next section of the CISSP tutorial, we’ll converse the reimbursement of CISSP to organizations and professionals.
If you want to pass the CISSP exam in the first try, get SPOTO 100% pass dump below to help you clear the CISSP exam easily!
Benefits of CISSP to Professionals and Organizations
CISSP provides lots and lots of benefits for professionals.
The benefits of CISSP for professionals are:
It helps in demonstrating a working knowledge of information security.
It ensures that the professionals have a commitment to the profession.
CISSP offers a career differentiator, with improved marketability and credibility.
CISSP would be providing the restricted reimbursement of precious resources like peer networking and idea exchange, for (ISC)² members.
CISSP indicates that certified information security professionals would be earning a worldwide average of 25% more than their non-certified complement, according to the Global Information Security Workforce Study.
It would be helping you to fulfill government as well as organization requirements for information security certification mandates.
CISSP Domains
CISSP Certification domains are going to be drawn the best practices across the globe while establishing a common framework of principles and terms to converse, deliberate, and tenacity matters pertaining to the profession, which.
CISSP CBK consists of the following eight domains:
Security and Risk Management
Asset Security
Security Engineering
Communications and Network Security
Identity and Access Management
Security Assessment and Testing
Security Operations
Software Development Security
Granted by the International Information System Security Certification Consortium, CISSP certification is an independent information security certification. 100% Latest and Valid CISSP Exam Questions for candidates to study and pass exams easily. CISSP exam dumps are frequently updated to help you for passing the exams quickly! You can pass your CISSP ISC Exam Fast by simulates a real exam testing environment.
Why SPOTO?
SPOTO stands for Service, professional, outstanding, teamwork, and obtain, which means we will offer professional and outstanding service to all customers. All candidates can pass their IT exam and get the certifications with the assistance of our passionate and professional service and products. SPOTO Club devotes to being a global e-learning platform, and ranks top with results: every two IT engineers get certified with SPOTO Club every day. SPOTO Club has its unique company culture. Following mottos reflect SPOTO Club’s culture: “When you decide to do CCIE, you’re already CCIE”, “Choose, move, persevere, go beyond”, “It’s easier to persevere with a group than to persevere by yourself”, “Every CCIE member has its own story “and” Being a CCIE is the beginning of your career ” Join SPOTO Club and be certified now.
SPOTO Club’s CISSP Training Features:
Passing Rate: 100%
21 Candidates Passed Last Week
Stable CISSP Dump
Latest Update
To acquire the study dumps that are being offered at the SPOTO Club, and gain your dream of obtaining the CISSP Certification.
-
- Cisco
- 556
- 2024-01-16
Cisco IOS Software would be containing a wide array of critical network services that would be designed for scalability, flexibility, as well as reliability to help them solve the most difficult problems which would be faced by enterprises and service providers. Customers could select the appropriate Cisco IOS Software feature sets to meet their evolving network requirements. Features like the NAT (Network Address Translation), DHCP (Dynamic Host Configuration Protocol), and HSRP (Hot Standby Router Protocol) could be easily deployed individually or in combination with each other around a wide range of Cisco hardware. If you wish to go in more depth, you should opt for the study dumps, offered at the SPOTO Club, they will help you out in gaining any Cisco Certification at the first attempt.
Cisco IP Services would be comprised of lots of basic as well as advanced building blocks that would be enabling the customers to:
Deploying an IP network with common end-to-end IP connectivity.
Managing their IP addressing requirements from a central location.
Controlling the IP addressing scheme utilized throughout the network.
Providing redundancy at major network connection points.
IP Addressing Services
An IP address is considered to be a 32-bit number written in dotted decimal notation: four 8-bit fields or octets, which would be converted from binary to decimal numbers, separated by dots. The first part of an IP address would be identifying the network on which the host would be residing while the second part would be identifying the particular host on the given network. The network number field is known as the network prefix. All hosts on a given network would be sharing the same network prefix but must have a unique host number. In classful IP, the class of the address would be determining the boundary between the network prefix as well as the host number.
Finding Feature Information
Your software would be releasing might not support all the features which would be documented in this module. For the latest caveats as well as feature information, observe the Bug Search Tool and the release notes for your platform as well as a software release. To find information about the features which would be documented in this module, as well as to observe a list of the releases in which each feature would be supported, see the feature information table. Utilize Cisco Feature Navigator for finding information about platform support as well as Cisco software image support.
IP Source Routing
The software would be examining the IP header options on every packet. It would be supporting the IP header options Strict Source Route, Loose Source Route, Record Route, as well as Time Stamp, which would be defined in RFC 791. If the software would be finding a packet with one of these options enabled, it would be performing the appropriate action. If it finds a packet with an invalid option, it would send an ICMP (Internet Control Message Protocol) parameter problem message to the source of the packet as well as discards the packet.
ICMP Overview
Created for the TCP/IP suite in RFC 792, the ICMP (Internet Control Message Protocol) would be designed for reporting a small set of error conditions. ICMP could also be reporting a wide variety of error conditions as well as provide feedback and testing capabilities. Each message utilizes a common format and is received and sent by utilizing the same protocol rules.
ICMP doesn’t ensure the delivery of datagrams or make IP reliable or the return of a control message. Some datagrams might be dropped without any report of their loss. The higher-level protocols that utilize IP must implement their reliability procedures if reliable communication would be required.
For more information, check out the training courses offered at the SPOTO Club, to gain success in your certifications.
-
- Cisco
- 814
- 2024-01-18
Realizing the benefits of intent-based networking as well as an open and extensible management platform, the need for intent-based networking would be growing as more segments of the business depend on secure, reliable digital networks. Cisco DNA Center would be providing a centralized management dashboard for complete control of this new network. Full automation capabilities for provisioning as well as change management are considered to be enhanced with intelligent analytics that would be pulling telemetry data from everywhere in the network. Applications, services, as well as users are considered to be prioritized which would be based on business goals, within policy parameters as well as security best practices. To gain more details regarding the Cisco DNA Center, you should opt for the training courses offered by the SPOTO Club.
Cisco DNA Center Benefits:
Simplifying network management. Managing your enterprise network over a centralized dashboard.
Deploying networks in minutes, not days. Utilizing intuitive workflows, Cisco DNA Center would be making it easy to design, provision, as well as apply policy across your network.
Lowering the costs. Policy-driven provisioning as well as guided remediation increase network uptime and reducing time spent managing simple network operations.
Transforming your network with cloud applications and services that would be benefitting from this intelligent network optimization.
What Cisco DNA Center Enables You To Do?
Save time by utilizing a single dashboard for managing and automating your network. Quickly scale your business with the help of intuitive workflows as well as reusable templates. Configuring and provisioning thousands of network devices across your enterprise in minutes, not hours. Deploying group-based secure access as well as network segmentation would be based on business needs.
With Cisco DNA Center, you would be applying policy to users as well as applications instead of your network devices. Automation would be reducing manual operations as well as the costs associated with human errors, resulting in more uptime as well as improved security. Assurance then assessing the network and utilizes context for turning data into cleverness, ensure that changes in the network device policies achieve your intent.
Monitoring, identifying, and reacting in real time to changing network as well as wireless conditions. Cisco DNA Center would be utilizing your network’s wired as well as wireless devices for creating sensors everywhere, providing real-time feedback which would be based on actual network conditions. The Cisco DNA Assurance engine would be correlating the network sensor insights with streaming telemetry as well as comparing this with the current context of these data sources. With a rapid check of the health scores on the Cisco DNA Center dashboard, you could see where there would be a performance based issue and identifying the most likely to cause in minutes.
With the newest Cisco DNA Center Platform, IT could now be integrating Cisco and third-party technologies into a single network operation for streamlining IT workflows as well as increasing business value and innovation. Cisco DNA Center would be allowing you to run the network with maximum performance, security, reliability, as well as open interfaces.
A Complete Platform
The Cisco DNA Center dashboard would be providing an intuitive and simple overview of network health and clear drill-down menus for identifying quickly as well as remediating issues. Orchestration and Automation provide zero-touch provisioning-based on profiles, facilitating network deployment in remote branches.
Advanced analytics and assurance capabilities utilizing deep insights from streaming telemetry, devices, and rich context for delivering, an uncompromised experience, while proactively optimizing, monitoring, and troubleshooting your wired as well as wireless network. Cisco DNA Center Platform would be extensibility interfacing with IT as well as business applications, integrating across IT operations as well as technology domains, and could manage heterogeneous network devices.
For more information regarding the Cisco DNA Center you should opt for the study dumps offered by the SPOTO Club.
-
- Cisco
- 549
- 2024-01-18
Solutions to the problem of data packet forwarding
In the previous two articles, we solved two problems: the routing conflicts in the local PE and the conflicts in the propagation process of the routing network, the problem of the schematic diagram RD format has been solved.
However, when data is forwarded, if there are 10.0.0.0/24 routes in the two local VRFs of the receiving PE, when it receives a packet with a destination address of 10.0.0.1, how does it know to send this packet? Which VRF is the CE connected to? Certainly need to add some information in the forwarded message. Of course, this information can be taken care of by RD. It is only necessary to transform the processing flow of MPLS VPN so that the data can also be carried when carrying RD.
But the RD has a total of 64 bits, which is too large, which will reduce the forwarding efficiency. To ensure efficiency, only a short, fixed-length mark is needed. Since the public network tunnel is already provided by MPLS, and MPLS supports nesting of multiple layers of labels, this label can be defined as the format of MPLS labels. Who will assign this label? The routing is private VPN, and LDP knows nothing about it. This task of assigning VPN private network routing labels can only be accomplished by extended BGP. Similar to the LDP protocol, label distribution is done before data forwarding occurs. The difference is that MP-IBGP assigns labels simultaneously with route exchange.
MP_REACH_NLRI
Address-family
VPN-IPv4 Address family
Next-hop
It is the PE router itself, usually the LOOPBACK address
NTRL
Lable
24 bits, same as mpls tag, but without ttl
Prefix
Rd:64bit+ip prefix
We know that BGP exchange routing is accomplished through NLRI (Network Layer Reachability Information). Through the transformation of BGP protocol, the modified MP-IBGP will append various information such as RD and label when NLRI information exchange. In this way, the routing exchange and data forwarding problems of the entire MPLS VPN are solved. Let's introduce the process of routing exchange and data forwarding of MPLS L3VPN.
MPLS L3VPN routing exchange and data forwarding process
As mentioned earlier, when MPLS L3VPN routes are exchanged, the PE router runs a single routing protocol (MP-IBGP) to exchange all VPN routes. To support the overlapping of VPN client spaces, add RD to the VPN address space to make it unique. And use the RT attribute to indicate the VRF to which the route belongs. We can summarize it as follows.
The routing exchange process of MPLS VPN is mainly divided into four parts:
■ Routing exchange between CE and PE;
■ The process of VRF route injection into MP-IBGP;
■ Public network label distribution process;
■ The process of MP-IBGP route injection into VRF.
Let's analyze the whole process of MPLS VPN routing exchange between PEs through examples.
Route exchange between CE and PE
Schematic diagram of route exchange between CE and PE
The exchange process is as follows:
Configure VRF for different VPN sites on the PE. PE maintains multiple independent routing tables, including public and private network (VRF) routing tables, including:
■ Public network routing table: contains all the routes between PE and P routers, and is backed by the backbone network IGP
Produce
■ Private network routing table: The routing and forwarding table that contains the reachable information of this VPN user.
Routing information is exchanged between PE and CE through standard EBGP, OSPF, RIP or static routes. In this process, except that the PE device needs to store the routes from the CE device in different VRFs (this is only related to the route receiving interface and has nothing to do with other MPLS VPN features), other operations are no different from ordinary route switching.
Static routing and RIP are standard protocols. All CE terminals can use the same routing protocol, but each VRF on the PE terminal needs to run a different instance, and there is no interference with each other. Simple introduction of each other. The situation of EBGP is similar to RIP. It is also ordinary EBGP instead of MP-EBPG, which only exchanges the VPN routes filtered by PE. However, choosing OSPF as the routing protocol between PE and CE is relatively complicated. Many modifications to OSPF are required to carry the LSAs of this site in the extended community attribute of BGP and exchange LSAs with OSPF in the remote VPN. OSPF in each site can have area 0, and the backbone network can be regarded as super area 0. At this time, OSPF changes from a two-level topology (backbone area + non-backbone area) to a three-level topology (super backbone area + backbone area + non-backbone area). For more detailed introduction of OSPF in MPLS VPN network, please refer to other related documents of MPLS VPN, which will not be described in detail here. This completes the route exchange process from CE to PE.
The process of VRF route injection into MP-IBGP
VRF route injected into MP-IBGP and route exchange diagram between PE
As shown in the figure, the process of injecting VRF routes into MP-IBGP and exchanging them between PE devices through MP-IBGP is as follows:
After receiving the routing information from the CE, the PE router needs to add RD to the route (RD is manually configured) to make it a VPN-IPv4 route. Then change the next hop attribute to yourself (usually your own loopback address) in the route advertisement, add a private network label to this route (generated automatically by the MP-IBGP protocol, no configuration required), and add the RT attribute (RT Need to be manually configured). After this series of work is completed, the PE sends it to all other PE neighbors. Other PE neighbors also perform the same operation to exchange routes on different CE ends.
Public network label distribution process
Schematic diagram of the public network label allocation process
The private network routing exchange between PEs needs to cross the MPLS backbone network. In this process, standard MPLS forwarding needs to be performed. Therefore, to properly route the route to the peer PE, you need to know the public network label that reaches the peer PE. As shown in the figure, the process of public network label assignment is as follows:
First, the PE and P routers learn the address of the next hop of the BGP neighbor through the backbone network IGP. By running the LDP protocol, labels are assigned, and LSP channels are established. The label stack is used for packet forwarding. The outer label is used to indicate how to reach the next hop of BGP. The inner label indicates the outbound interface of the packet or which VRF (which VPN) it belongs to. MPLS node forwarding is based on the outer label, regardless of the inner label. At this time, through the outer label space of MPLS, normal routing exchange can be performed between PE devices.
The process of MP-IBGP route injection into VRF
Schematic diagram of the process of MP-IBGP route injection into VRF
As shown in the figure, after receiving the route sent by the sending PE, the receiving PE changes the VPN-v4 route to an IPv4 route, and adds the route entry to the corresponding VRF according to the import RT attribute of the local VRF. The private network label Keep it, record it in the forwarding table, and use it for forwarding. It is then introduced by the routing protocol of this VRF and passed to the corresponding CE. When sending to CE, the next hop is the interface address of the receiving PE. This completes the process of injecting MP-IBGP routes into VRF.
After the above four steps, the routing exchange of the entire MPLS VPN network is completed. At this point, the VPN is constructed and normal business data can be forwarded.
Conclusion
In those articles, <mpls vpn architecture-1、2、3> I will introduce the what is rd and rt value.
And what is vrf, if you want to know more , please view those articles in our blog website.
If you desire to pass the Cisco exams and looking for the most reliable and clear to understand the material so, now it is very easy for you to get it at SPOTO. We are presenting you here the most up-to-date questions & answers of Cisco exams, accurate according to the updated exam.
-
- Cisco
- 475
- 2024-01-17
Virtualization is considered to be the creation of a virtual rather than actual versions of something, like an operating system (OS), a server, a storage device or network resources. We would be discussing the types of virtualization, but before that, if you wish to gain more information regarding this, you should gain the study dumps offered by the SPOTO Club.
Types of virtualization
Network virtualization
It is considered to be a method of combining the available resources in a network by dividing up the available bandwidth into channels, each of which would be independent of the others and could be assigned or reassigned for a particular server or device in real-time. The idea would be that virtualization disguises the true complexity of the network by unraveling it into convenient parts; much like your partitioned hard drive makes it quite easier for managing your files.
Storage virtualization
It is considered to be the pooling of physical storage from multiple network storage devices into what appears to be a single storage device that would be managed from a central console. It is commonly utilized in storage area networks.
Server virtualization
It is considered to be masking of server resources which would be including the number and identity of individual physical servers, processors as well as operating systems from server users. The intention is believed to spare the user from having to manage and understand complicated details of server resources while increasing resource sharing as well as utilization and maintaining the capacity to expand later.
Data virtualization
It is believed to be abstracting the traditional technical details of data as well as data management, like location, performance or format, in favor of broader access as well as more resiliencies tied to business needs.
Desktop virtualization
It is vitalizing a workstation load rather than a server. This would be allowing the user for accessing the desktop remotely, typically utilizing a thin client at the desk. Since the workstation is considered to be running essentially in a data center server, access to it can be both more portable and secure.
Application virtualization
It is abstracting the application layer away from the operating system. This way, the application could run in an encapsulated form without being depended upon on by the operating system beneath. This could allow a Windows application to run on Linux and vice versa, in addition to adding a level of separation.
Benefits
Virtualization would be providing the companies with the benefit of maximizing their output. An additional benefit for both data centers and businesses would be including the following:
Single-minded servers:
Virtualization provides quite a cost-effective way of separating email, database as well as web servers, creating a more comprehensive and trustworthy system.
Accelerated deployment and redeployment:
When a physical server would be crashing, the backup server might not always be ready or up-to-date. There might not be an image or clone of the server available. If this is the case, then the redeployment process could be considered tedious and time-consuming.
Reducing heat as well as improved energy saving:
Companies that would be utilizing a lot of hardware servers risk overheating their physical resources. The best way for preventing this from happening is to decrease the number of servers utilized for data management, and the best way to do this would be through virtualization.
Better for the environment:
Companies, as well as data centers that would be exploiting abundant amounts of hardware, leave a hefty carbon footprint; they must take accountability for the pollution they are generating.
If you wish to have more details related to the Device Virtualization Technologies, you should consider the study dumps offered by the SPOTO Club.
-
- python
- 588
- 2024-01-15
Python is believed to be an interpreted, high-level, general-purpose language of programming, created by Guido van Rossum and it was first released in 1991. Python's design would be philosophy emphasizing code readability with its notable utilize of significant whitespace. Its language constructs as well as object-oriented approach aiming for helping programmers write clear, logical code for small as well as large-scale projects. It would be supporting multiple programming paradigms, which would be including structured (particularly, procedural,) object-oriented, as well as functional programming.
Python is often described as the batteries that included language because of its comprehensive standard library. Python was conceived in the late 1980s as a descendant of the ABC language. Python 2.0 was released in 2000, which would be introduced features such as list comprehensions and a garbage collection system capable of collecting reference cycles. Python 3.0, which was released in 2008, would be a major revision of the language that isn’t entirely backward-compatible, as well as much Python 2 code doesn’t run unmodified on Python 3. Before we move further, if you wish to gain hands-on experience, you should opt for the training courses offered at the SPOTO Club.
The Python 2 language, i.e. Python 2.7.x, has been officially discontinued on 1 January 2020 after which security patches as well as other improvements won’t be released for it. With Python 2's discontinuing, only Python 3.5.x as well as later are supported. Python would be interpreting are available for lots of operating systems. A global community of programmers maintains and develops CPython, an open-source reference implementation. A non-profit organization, the Python Software Foundation, would be managing and directing resources for the development of Python and CPython.
Its implementation would have begun in December 1989. Van Rossum would be shouldered sole responsibility for the project, as the lead developer, until 12 July 2018, when he would be announcing his permanent vacation from his responsibilities as Benevolent Dictator for Life of Python, a title which was bestowed upon him by Python for reflecting his long-term commitment as the project's chief decision-maker. He would be now sharing his leadership as a member of the steering council of five-person. In January 2019, active Python core developers later on elected Brett Cannon, Barry Warsaw, Nick Coghlan, Carol Willing as well as Van Rossum to a five-member Steering Council which would be leading to the project.
On 16 October 2000, Python 2.0 was released with lots of major new features, which would be including a cycle-detecting garbage collector and support for Unicode. On 3 December 2008, Python 3.0 was released. It would be a major revision of the language that isn’t completely backward-compatible. Many of its major features would be backported to Python 2.6.x as well as 2.7.x version series. Releases of Python 3 would be including the 2to3 utility, which would be automated, at least partially, the translation of Python 2 code to Python 3.
Python 2.7's would be end-of-life date was previously set at 2015 than would be deferred to 2020 out of concern that a large body of existing code couldn’t be easily be forward-ported to Python 3.
Python Scripting
A script is utilized for automating certain tasks in a program. It could be able to run by itself as well as it is less code-intensive whereas modules in python would be referred to as a library that couldn’t run on its own. It would be required to gain imported in order to utilize it.
Python Scripting Examples
Here are some examples of Python scripting that you could utilize for solving common real-world problems.
Adding a Counter to a Python Script
Date and Time Manipulation
Defining Useful Utility Functions
Getting and Setting Database Information
Message Manipulation
Adding or Deleting Rows and Retrieving a Table
String Manipulation
Using Python to Converting Text to PDF Format
So, if you wish to have more information regarding the Python Scripting, you should opt for the study dumps, which are being offered at the SPOTO Club.
-
- Cisco
- 1446
- 2024-01-16
Cisco DNA Center is considered to be at the heart of Cisco’s intent-based network architecture. Cisco DNA Center would be supporting the expression of business intent for network use cases, like base automation capabilities in the enterprise network. The Assurance and Analytics features of Cisco DNA Center would be providing end-to-end visibility into the network with full context through data as well as insights.
Intent API (Northbound)
The Intent API is considered to be a Northbound REST API that would be exposing specific capabilities of the Cisco DNA Center platform. The Intent API would be providing the policy-based abstraction of business intent, which would be allowing focus on an outcome rather than struggling with individual mechanisms steps. The RESTful Cisco DNA Center Intent API would be utilizing HTTPS verbs (GET, POST, PUT, and DELETE) with JSON structures for discovering and controlling the network.
Multivendor Support (Southbound)
Cisco DNA Center would be allowing customers for managing their non-Cisco devices through the utilization of an SDK (Software Development Kit) that could be utilized for creating Device Packages for third-party devices. Encapsulation of third-party components would be allowed for an integrated view of the network consistent with the DNA Center abstraction. A Package Device would be enabling the Cisco DNA Center for communicating to third-party devices by mapping Cisco DNA Center features to their southbound protocols.
Events and Notifications (Eastbound)
The Cisco DNA Center platform would be providing the ability for establishing a notification handler when specific events would be triggered, like the Cisco DNA Assurance as well as Automation (SWIM) events. This mechanism would be enabling external systems to take action in response to an event. Notifications might also be triggered by events inner DNA Center events.
Integration API (Westbound)
Integration capabilities are considered to be part of Westbound interfaces. In order to meet the need for scaling and accelerating operations in modern data centers, IT operators require intelligent, end-to-end workflows that would be built with open APIs. The Cisco DNA Center platform would be providing mechanisms for integrating Cisco DNA Assurance workflows as well as data with third-party ITSM (IT Service Management) solutions. Before we discuss about the vManage APIs, you should opt for the training courses which are being offered at the SPOTO Club, if you wish to gain more information regarding the APIs for Cisco DNA Center.
vManage APIs
The vManage REST API library, as well as documentation, would be bundled with and installed on the vManage web application software.
Performing REST API Operations on a vManage Web Server
For transferring data from a vManage web server utilizing a utility like the Python, you should follow this procedure:
Establishing a session to the vManage web server.
Issuing the desired API call.
Establishing a Session to the vManage Server
When you would be utilizing a program or script for transferring data from a vManage web server or perform operations on the server, you should be first establishing an HTTPS session to the server.
You could find the documentation for this call under the Monitoring Device Details resource collection. This call is considered to be a GET request, as well as it would be also indicating the URL for utilizing to send the request. The call returns a JSON object that is considered to be large because it would be containing device information for all devices in the network. The output would be returned on a single line. For filtering the results of this call so you would be gaining the information only for a single device, you add query string parameters.
If you wish to acquire more knowledge regarding APIs, you should opt for the training courses which are being offered at the SPOTO Club.
-
- Cisco
- 778
- 2024-01-17
While there would be great advances that are made in the speed as well as ease of implementation of Wi-Fi networks, the basic nature of RF (radio frequency) is considered to be unchanged generally. Increasing the number of users who could access the WLAN in a small physical space would be remaining a challenge. The general concepts would be underlying high-density Wi-Fi design that remains true for lots of environments. But it is considered to be very important to note that the solutions and content presented here won’t fit every WLAN designing scenario. Rather, the intention of the guide is considered to explain the challenges in WLAN design for high-density client environments as well as to offer successful strategies so that engineers and administrators understanding them and would be able to articulate the impact design decisions would have. Before we discuss it further, if you wish to have hands-on experience of the same, you should opt for the training courses offered by the SPOTO Club, to ensure your success.
Targeting Environmental Characteristics for WLANs in Higher Education Environments
High-density WLAN design would be submitted to any environment where client devices would be situated in densities would be greater than coverage opportunity of normal enterprise deployment, in this case, a traditional carpeted office. For reference, a typical office environment would be having indoor propagation characteristics for signal attenuation. User density is considered to be a critical factor in the design. Aggregate available bandwidth would be delivered per radio cell, as well as the number of users and their connection characteristics like the speed, radio type, duty cycle, band, signal, and SNR occupying that cell would be determining overall bandwidth available per user.
A typical office environment, Figure 1, might be having APs deployed for 2,500 to 5,000 square feet with a signal of -67 decibels in dBm (millowatts) coverage as well as a maximum of 20 to 30 clients per cell. That would be a density of one user every 120 square foot (sq. ft.) as well as yields a minimum signal of -67 dBm.
In deploying and planning such a WLAN, an AP is considered to be naturally placed in an area predictable for having a higher user density, like in a conference room, while common areas are considered to be left with less exposure. In this way, preplanning for high-density areas would be anticipated. Conference rooms are commonly placed in clusters, so it is considered to be the best for designing for the maximum capacity of the area.
In a high-density environment like the lecture hall or auditorium, the densities of users in the occupied space would be increasing dramatically. User seating is clustered typically very much close together for achieving high occupancy. The overall dimensions of the space are considered to be really only useful for getting an idea of the free space path loss of the AP signal. User densities aren’t evenly dispersed over the complete space as stages, aisle ways, and podiums represent a percentage of space that would be relatively unoccupied.
The single biggest source of interference in the room would be the client devices themselves. For each user sitting in the auditorium that could rest their hand comfortably on the back of the seat in front of them, the distance would be approximately 3 feet, with an average seat size of 24 inches. This yields what would be defined as a high-density environment, with less than 1 sq. meter per device deployed supercilious one or more devices connected per seat.
So, if you wish to gain more information regarding the WLAN Design Principles, you should opt for the training courses which are offered at the SPOTO Club.
-
- Cisco
- 510
- 2024-01-16
The Solution to the Problem of Conflicts When Routing Is Transmitted in the Network Why do we need RD value? A very straightforward example of this problem is the technology you will encounter in the CCIE exam, and if you are not familiar with the principle of RD worth, and the configuration of the RD value in the exam is deleted by mistake, then you cannot pass CCIE (EI) LAB exam, because deleting an RD value will cause some configurations to be automatically deleted.
After successfully solving the problem of local routing conflicts, in the next step we need to resolve the conflicts of routing when passing through the network. Standard BGP can only handle IPv4 routing, so if different VPNs use the same IPv4 address prefix, the routing of different VPNs cannot be distinguished at the receiving end. Using the RT attribute can partially solve this problem, but it also has certain limitations. Let's analyze how to solve this problem and its limitations through RT.
■ After PE receives the routes from different VPNs, it decides which VRF the route enters according to the RT attribute, so as to ensure that the routes of different VPNs are not comparable and the operation can be carried out normally;
■ When the route is revoked, the BGP packet has no attributes, and RT certainly will not work, which will cause the same route in all VPNs to be revoked. Therefore, although RT has this function, it is not easy to use all the time. There must be a tag that can be bound to the IPv4 address to fundamentally solve this problem-we call this tag RD. RD is a mark attached to the front of the IPv4 address, and its format is shown in the figure: The type field defines two values: 0 and 1. For type 0, the manager sub-area includes 2 bytes, and the assigned value field includes 4 bytes. The manager sub-area uses an autonomous system number (ASN) to assign a value sub-area to the value space managed by the service provider. Type 0 cannot use private autonomous system numbers, which may cause conflicts. If you want to use a private autonomous system, you can use type 1. For Type 1, the manager sub-region includes 4 bytes, and the assigned value field includes 2 bytes. The manager sub-area uses IPv4 addresses and assigns value sub-areas to the value space managed by the service provider. The structure of RD is similar to RT, but they are essentially different.
RT is an extended attribute of BGP routing, and RD is appended to the IPv4 address and exists as part of the address. This needs everyone's attention. The characteristics of some applications of RD are as follows:
After adding RD to the IPv4 address, it becomes a VPN-IPv4 address family. In theory, it is possible to configure an RD for each VRF, but it must be guaranteed that this RD is unique globally. It is generally recommended to configure the same RD for each VPN. The VPN-IPv4 address is only used inside the service provider's network. It is added when the PE advertises the route, and it is placed in the local routing table after the PE receives the route to compare it with the route received later. The CE does not know that the VPN-IPv4 address is used. When it traverses the backbone of the provider, the VPN-IPv4 address is not carried in the packet header of the VPN data traffic. RD is only used when the backbone network routing protocol exchanges routes. And the standard route that the PE receives from the CE is an IPv4 route. If it needs to be advertised to other PE routers, an RD needs to be added to this route.
Because RD has these characteristics, if the same address exists in two VRFs, but the RD is different, then the two VRFs must not be able to visit each other, nor can indirect mutual visits. This is because the data packet does not carry RD when data is forwarded, so that when the data arrives at the destination, the PE will find the route entry to the same destination in different VRFs, resulting in incorrect forwarding. Although RD is carried in the process of routing and exchanging PE equipment, RD does not affect the routing between different VRFs and the formation of VPN. These things are handled by RT. The difference between RD and RT Features of RD In principle, the role of RD is to change the IPv4 address into a globally unique VPNv4 address. When overlapping IPv4 addresses appear in different VPNs, RD can distinguish them. The format used is usually ASN: N, and some are based on IP address formats, such as X.X.X.X: N, but the latter is not commonly used. So as long as the VPN addresses do not overlap, RD can be arbitrarily matched. According to the characteristics of the network, we use the ASN: N method and use this AS number + N (N can be arbitrarily valued). It is generally more common to use the same RD in the same VPN.
VPN-sale
ASN :100
VPN-fifinance
ASN :200
VPN-manage
ASN :300
ASN is the AS number
Features of RT RT plays a very obvious role in MPLS VPN. It is used to control the isolation and partial interworking of VPN. The format is the same as RD. For different VPNs, it is required to define different RT values. If there are interworking requirements, they are controlled by RT attributes, which are divided into export and import attributes. The export attribute represents an attribute that is attached when a VPN route is sent. When another PE device receives this route, the import attribute determines whether to receive or which VPN to associate with when receiving the route. So for the definition of VPN, if the three VPNs do not require interworking, then:
VPN-sale
export=ASN :100
import=ASN :100
VPN-fifinance
export=ASN :200
import=ASN :200
VPN-manage
export=ASN :300
import=ASN :300
Conclusion: In the chapter <mpls vpn architecture-3>, we will talk about the third problem of traditional VPNs-packet forwarding problem. Even if the routing table conflict is successfully resolved, when the PE receives an IP packet , How can it know which VPN to send to? Because the only information available in the IP header is the destination address. This address may exist in many VPNs. SPOTO aims to help all candidates to prepare and pass Cisco CCNA, CCNP, CCIE Lab, CISSP, CISA, CISM, PMP, AWS and other IT exams in the first try. Hurry up to contact us!
Related Articles:
1. MPLS VPN Architecture-1
2. MPLS VPN Architecture-2